| โครงสร้างข้อมูล (Data Structure) คืออะไร
โครงสร้างข้อมูล (Data Structure) - บิท (Bit) คือ ข้อมูลที่มีขนาดเล็กที่สุด เป็นข้อมูลที่เครื่องคอมพิวเตอร์เข้าใจ และใช้งานได้ ได้แก่ 0 หรือ 1 - ไบท์ (Byte) หรือ อักขระ (Character) คือ ตัวเลข หรือ ตัวอักษร หรือ สัญลักษณ์พิเศษ จำนวน 1 ตัว - ฟิลด์ (Field) หรือ เขตข้อมูล คือ ไบท์ หรือ อักขระตั้งแต่ 1 ตัวขึ้นไปรวมกันเป็นฟิลด์ เช่น เลขประจำตัว หรือ ชื่อพนักงาน - เรคคอร์ด (Record) หรือระเบียน คือ ฟิลด์ตั้งแต่ 1 ฟิลด์ขึ้นไป ที่มีความสัมพันธ์เกี่ยวข้องกันมารวมกัน - ไฟล์ (File) หรือ แฟ้มข้อมูล คือ หลายเรคคอร์ดมารวมกัน เช่น ข้อมูลที่อยู่นักเรียนมารวมกัน - ฐานข้อมูล (Database) คือ หลายไฟล์ข้อมูลมารวมกัน เช่น ไฟล์ข้อมูลนักเรียนมารวมกันในงานทะเบียน แล้วรวมกับไฟล์การเงิน |
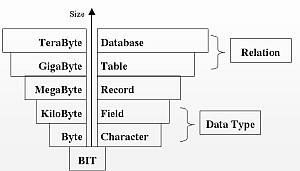

| ศัพท์เทคนิค (Technical Terms) |
|
| ความรู้เบื้องต้นเกี่ยวกับการพัฒนาระบบ |
การพัฒนาโปรแกรมประกอบด้วยขั้นตอนพื้นฐาน 7 ขั้นตอน [3]p.19 1. กำหนดปัญหา (Define the Problem) 2. ร่างรายละเอียดแนวทางแการแก้ไขปัญหา (Outline the Solution) 3. พัฒนาอัลกอริทึม (Develop Algorithm) อาจนำเสนอด้วย Flowchart, DFD, ER หรือ UML 4. ตรวจสอบความถูกต้องของอัลกอริทึม (Test the Algorithm for Correctness) 5. เขียนโปรแกรม (Programming) 6. ทดสอบโปรแกรม (Testing) 7. จัดทำเอกสารและบำรุงรักษาโปรแกรม (Document and Maintain the Program)
|
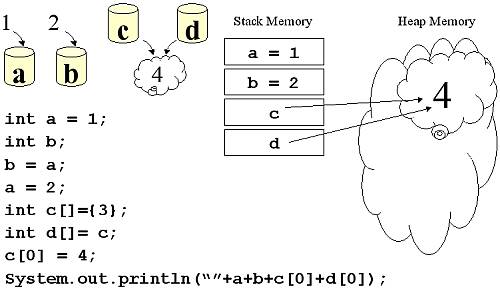 ภาพแสดง ความแตกต่างของ
ภาพแสดง ความแตกต่างของ | อัลกอริทึม (Algorithm) http://www.thaiall.com/datastructure/pseudocode.htm |
ต.ย. อัลกอริทึมที่ 1 : ต้มมาม่า [3]p.25 1. หามาม่าไว้ 1 ซอง 2. ฉีกซองมาม่าและเทลงถ้วยเปล่า 3. ฉีกซองเครื่องปรุง แล้วเทลงถ้วยเดิม 4. ต้มน้ำให้ร้อนได้ที่ แล้วเทลงถ้วย 5. ปิดฝาไว้ 3 นาที 6. เปิดฝา แล้วรับประทาน | คำถาม : ต้มมาม่า 1. มีขั้นตอนใดสลับกันได้ 2. ถ้าเปลี่ยนข้อความ จะเปลี่ยนอย่างไร 3. ถ้าทำหลายถ้วยจะทำอย่างไร ? คน 3 คนใครอายุมากที่สุด และเป็นเท่าใด |
ต.ย. อัลกอริทึมที่ 2 : หาค่าเฉลี่ย ใช้ Pseudo Code 1. set variable 2. loop | คำถาม : หาค่าเฉลี่ย 1. เขียนเป็นภาษาไทยอย่างไร 2. แต่ละบรรทัดในจาวาคืออะไร 3. สลับบรรทัดใดในจาวาได้บ้าง 4. ไม่มีตัวแปร avg จะได้หรือไม่ | 1. 2. 3. 4. 5. | ภาษาจาวา
byte x;
int i = 0;
int total = 0;
while (i < 5) {
x = System.in.read();
total = total + x;
i++;
}
double avg = total/i;
System.out.println(avg);
|
| ปฏิบัติการพื้นฐานของเครื่องคอมพิวเตอร์ [3]p.37 |
1. รับข้อมูล (input device) 2. แสดงผล (output device) 3. คำนวณ (limit and sequence) 4. กำหนดค่าตัวแปร (storage) 5. เปรียบเทียบ หรือเลือกทำงาน (compare or decision) 6. ทำซ้ำ (repeation or loop) |
| หน่วยความจำ (Memory) |
โครงสร้างหน่วยความจำ (Memory Architecture) การจัดสรรหน่วยความจำ (Memory Allocation) - แบบคงที่ (Static) - แบบเปลี่ยนแปลงได้ (Dynamic) ตารางแฟท (FAT = File Allocatio Table) - Directory Table - Memory Pointer File Attribute - Archive file - System file - Readonly file - Hidden file |  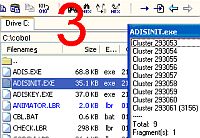 ต.ย. แฟ้ม adisinit.exe มีขนาด 35.1 KB ใช้พื้นที่ 9 Block ๆ ละ 4 KB เพราะเครื่องนี้แบ่ง 1 Cluster มีขนาด 8 Sectors |
| ชนิดข้อมูลนามธรรม (Abstract Data Type : ADT) |
ชนิดข้อมูลนามธรรม (Abstract Data Type) คือ เครื่องมือกำหนดโครงสร้างข้อมูลที่ประกอบด้วยชนิดของโครงสร้างข้อมูล รูปแบบการดำเนินการ หรือแยกได้ 3 ส่วนคือ รูปแบบข้อมูล (Element) โครงสร้าง (Structure) และ การดำเนินการ (Operations) [4]p.25
|
| ประสิทธิภาพของอัลกอริทึม (Algorithm Efficiency) |
ประเด็นที่ใช้วัดประสิทธิภาพ [3]p.58 1. เวลาที่ใช้ประมวลผล (Running Time) 2. หน่วยความจำที่ใช้ (Memory Requirement) 3. เวลาที่ใช้แปลโปรแกรม (Compile Time) 4. เวลาที่ใช้ติดต่อสื่อสาร (Communication Time) | ปัจจัยที่ส่งผลต่อความเร็วในการประมวลผล 1. ความเร็วของเครื่องคอมพิวเตอร์ (CPU, Main Board) 2. อัลกอริทึมที่ออกแบบเพื่อใช้งาน 3. ประสิทธิภาพของตัวแปลภาษา 4. ชุดคำสั่งที่สั่งประมวลผลเครื่องคอมพิวเตอร์ 5. ขนาดของหน่วยความจำในเครื่องคอมพิวเตอร์ 6. ขนาดของข้อมูลนำเข้า และผลลัพธ์จากการประมวลผล |
| - การวัดประสิทธิภาพของอัลกอริทึม (Efficiency Algorihm)
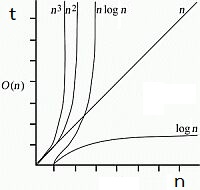
- การวิเคราะห์บิ๊กโอ (Big-O Analysis) - ขั้นตอนการเปลี่ยน f() เป็น Big-O Notation [4]p.23 |
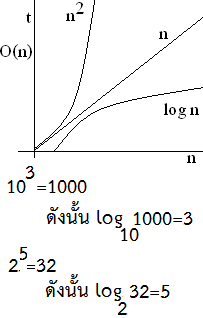 |
ความหมายของลอการิทึม - ลอการิทึม (อังกฤษ: logarithm) เป็นการดำเนินการทางคณิตศาสตร์ที่เป็นฟังก์ชันผกผันของฟังก์ชันเลขชี้กำลัง - ค่าลอการิทึมของจำนวนหนึ่งโดยกำหนดฐานไว้ให้ จะมีค่าเทียบเท่ากับ การเอาฐานมายกกำลังค่าลอการิทึม ซึ่งจะให้คำตอบเป็นจำนวนนั้น ลูปแบบเพิ่ม 2 เท่า for(i=1;i<1000;i*=2){ echo i; } เช่น 1 2 4 8 16 32 64 ลูปแบบลด 2 เท่า for(i=1;i<1000;i/=2){ echo i; } เช่น 1000 500 250 125 62.5 31.25 |
- ต.ย.1 จงหาผลบวกของการบวกจำนวนที่เริ่มต้นตั้งแต่ 1 - 10 ดร.บุญญฤทธิ์ อุยยานนวาระ เปรียบเทียมประสิทธิภาพของ Big-O กับความเร็วของยวดยาน ดังนี้ + O(1) เหมือนเครื่องว๊าบ หรือเครื่องย้ายมวลสาร คือ ไกลแค่ไหนไม่เกี่ยว + O(log n) เหมือนเครื่องบินโดยสาร + O(n) - เหมือนรถฟอร์มูล่าวัน ระยะทางไกลขึ้น ก็ขับนานขึ้น + O(n log n) - เหมือนรถยนตทั่วไป ยิ่งไกลยิ่งช้า + O(n^2) - เหมือนมอร์เตอร์ไซด์ + O(n^3) - เหมือนจักรยาน + O(2^n) - เหมือนคนเดิน | การทำซ้ำ หรือลูป มีหลายแบบ - ลูปแบบเชิงเส้น (Linear Loops) - ลูปแบบลอการิธมิค (Logarithmic Loops) - ลูปแบบซ้อน (Nested Loops) |
| อาร์เรย์ (Array) |
- อาร์เรย์หนึ่งมิติ (One Dimension Array) 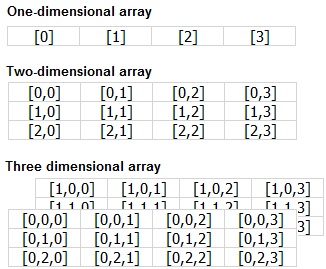 http://msdn.microsoft.com |
| เรคอร์ด (Record) |
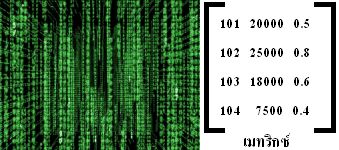
ระเบียนข้อมูล หรือเรคอร์ด |  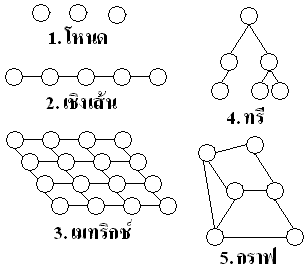 |
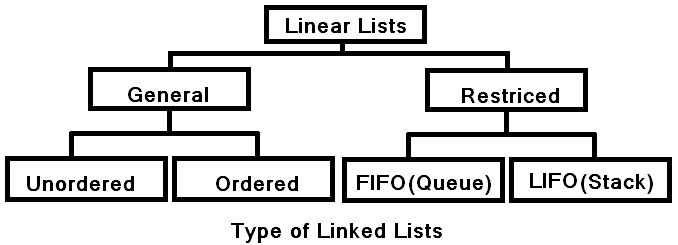
| ลิงค์ลิสต์ (Linked List) [3]p.101 |
การดำเนินงานพื้นฐานของลิสต์ (Basic Operations of List) 1. การแทรก (Insertion) 2. การลบ (Deletion) 3. การปรับปรุง (Updation) 4. การท่องเข้าไปในลิสต์ (Traversal) |
| ตัวชี้ข้อมูลด้วยภาษาปาสคาล [2]p.220 Binary Tree type nodeptr = ^trnode; trnode = record end; 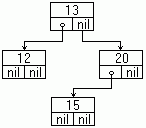 | ตัวชี้ข้อมูลด้วยภาษาซี [3]p.193 Abstract Data Type ของ คิว typedef struct node { } QUEUE_NODE; typedef struct { } QUEUE; QUEUE* createQueue (void); bool enqueue (QUEUE* q, void* itemptr); |
| สร้างคิว [2]p.221 var root : nodeptr; begin maket(root); procedure maket(var t:nodeptr); begin end; | สร้างคิว QUEUE* createQueue (void) { } |
| เพิ่มข้อมูลในคิว [2]p.224
new(n); inserted := false; o := t; while not inserted do begin if num <= o^.data then else end; n^.data := num; n^.leftptr := nil; n^.rightptr := nil; | เพิ่มข้อมูลในคิว bool enqueue (QUEUE* q, void* itemptr) { } |
// Test of Linked List #1/2
class BlankNode {
public Object data;
public BlankNode next;
public BlankNode(Object data) {
this.data = data;
this.next = null;
}
public String toString() {
return data.toString();
}
}
|
| สแต็ก (Stack) |
- Push คือ เพิ่มข้อมูลลงสแต็ก [3]p.137 - Pop คือ นำข้อมูลบนสุดไปใช้ และลบออกจากสแต็ก - Stack Top คือ นำข้อมูลบนสุดไปใช้ แต่ไม่ลบออกจากสแต็ก - Infix คือ นิพจน์ทางคณิตศาสตร์ทั่วไปที่เราใช้กัน [3]p.159 - Postfix คือ นิพจน์ที่โอเปอเรเตอร์อยู่หลังโอเปอแรนต์ เช่น AB+ - Prefix คือ นิพจน์ที่โอเปอเรเตอร์อยู่หน้าโอเปอแรนต์ เช่น +AB อาจกล่าวอีกอย่างได้ว่า - ตัวดำเนินการ คือ เครื่องหมายทางคณิตศาสตร์ (Operator) - ตัวถูกดำเนินการ คือ สัญลักษณ์หรือตัวแปร (Operand) - Infix คือ ตัวดำเนินการอยู่ระหว่างตัวถูกดำเนินการ - Postfix คือ ตัวดำเนินการอยู่หลังตัวถูกดำเนินการ - Prefix คือ ัวดำเนินการอยู่ก่อนตัวถูกดำเนินการ กฎเกณฑ์สำหรับการแปลงนิพจน์ Infix มาเป็นนิพจน์ Postfix [3]p.160 ขั้นตอนที่ 1. ใส่เครื่องหมายวงเล็บให้ทุกนิพจน์ แยกลำดับการคำนวณ เช่น คูณ หาร มาก่อน บวก ลบ ขั้นตอนที่ 2. เปลี่ยนสัญลักษณ์ Infix ในแต่ละวงเล็บให้มาเป็นสัญลักษณ์แบบ Postfix โดยเริ่มจากวงเล็บในสุดก่อน ขั้นตอนที่ 3. ถอดวงเล็บออก |
ฟังก์ชันที่เกี่ยวกับสแต็ก [3]p.143 1. Create Stack คือ สร้างหัวสแต็ก 2. Push Stack คือ เพิ่ม 3. Pop Stack คือ ดึงออก 4. Stack Top คือ อ่านบนสุด 5. Empty Stack คือ ตรวจการว่าง 6. Full Stack คือ ตรวจการเต็ม 7. Stack Count คือ นับสมาชิก 8. Destroy Stack คือ ลบข้อมูลและหัวสแต็ก
|
| กฎเกี่ยวกับการแปลง infix เป็น postfix 1. ถ้า input เป็น operand ให้ออกเป็น postfix 2. ถ้า input เป็น operator แล้ว stack ว่างให้ลง stack 3. ถ้า input มีลำดับสำคัญกว่าใน stack ให้ลง stack 4. ถ้า input สำคัญน้อยกว่าใน stack ย้ายใน stack ไปเป็น postfix ต.ย. 1 แปลง A - B / C เป็น Postfix โจทย์ให้ฝึกแปลงจาก infix เป็น postfix 1. a + b - c * d / e - f + g * h 2. a * b - c * d + e - f + g * h 3. a + b * c * d / (e * f) * g + h 4. a + b - (c * d) - e - f + g - h 5. a + (b + c) * d / e + f / g * h 6. a / b * c * d * (e - f) + g ^ h 7. (a ^ b) / c * d / e - f + g + h 8. a * b ^ c * ((d - e) - f) * g - h 9. a + b - c ^ ((d - e) - f) * (g - h) 10. a / (b + c) * (d + (e + f)) ^ g + h + stack_cal_postfix 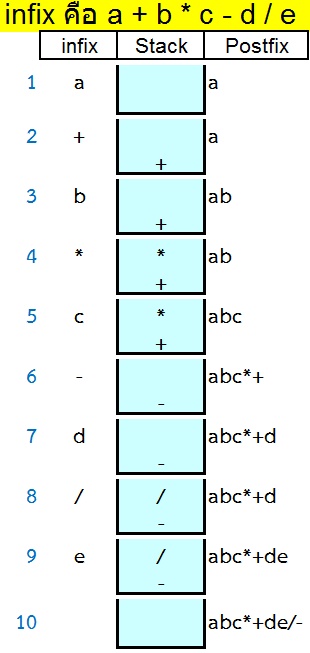
|
| คิว (Queue) : คิว ใน wikipedia.org |
| - คิว (Queue)
- ตัวอย่างของคิวที่พบได้ในปัจจุบัน เช่น แถวซื้ออาหาร รอฝากเงิน คิวรอพริ้น เป็นต้น |  |
| ฟังก์ชันที่เกี่ยวกับคิว ประกอบด้วย enqueue, dequeue, queue front, queue rear |
| ทรี (Tree) : |
| - ไบนารีเสิร์ชทรี (Binary Search Tree)
- เอวีแอลเสิร์ชทรี (AVL Search Tree) - ฮีพทรี (Heap Tree) แนวคิดพื้นฐานของทรี [3]p.211 - โหนดราก (Root Node) คือ โหนดแรก เริ่มต้นที่อยู่บนสุด - โหนดพ่อ (Parents) คือ โหนดที่มีลูก - โหนดลูก (Children) คือ โหนดที่มีพ่อ - โหนดพี่น้อง (Siblings) คือ โหนดเป็นพี่่น้อง และนับแยกครอบครัว - โหนดใบ (Leaf Node) คือ โหนดที่่อยู่ปลายสุด - ดีกรีทั้หมดของทรี คือ ที่มีฐานะเป็นลูกทั้งหมด - ดีกรีทั้หมดของพ่อ A คือ ที่มีฐานะเป็นลูกทั้งหมดของ A - ระดับความสูง (Level) คือ จำนวนชั้นของทรี 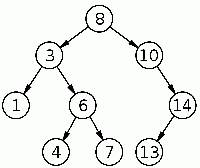 Binary Serch Tree 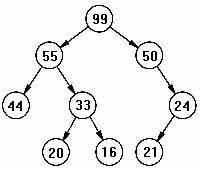 Heap Tree |
| กราฟ (Graph) |
| การจัดเก็บข้อมูลในกราฟ 1. เมทริกซ์ประชิด (Adjacency Matrix) 2. ลิสต์ประชิด (Adjacency List) - ดีกรี (Degree) คือ จำนวนของเวอร์เท็กซ์ประชิด - เอาต์ดีกรี คือ เส้นที่ออกจากเวอร์เท็กซ์ - อินดีกรี คือ เส้นที่เข้ามายังเวอร์เท็กซ์ - เส้นทาง (Path) คือลำดับของเวอร์เท็กซ์ที่ประชิดต่อกันไปยังตัวถัดไป - เอดจ์ (Edges) คือ เส้นที่เชื่อมระหว่างเวอร์เท็กซ์ แบบไม่มีทิศทาง - อาร์ค (Arcs) คือ เส้นที่เชื่อมระหว่างเวอร์เท็กซ์ แบบมีทิศทาง - เวอร์เท็กซ์ (Vertex) คือ โหนด | 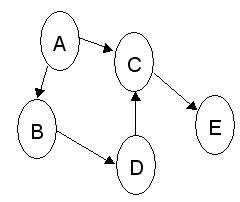 |
| การเรียงลำดับข้อมูล (Sorting) |
| สำหรับอธิบายการจัดเรียงแบบน้อยไปมาก เป็นการเริ่มต้น - แบบเลือก (Selection Sort) O(n - แบบฮิพ (Heap Sort) - แบบแทรก (Insertion Sort) - แบบฟองสบู่ (Bubble Sort)
|
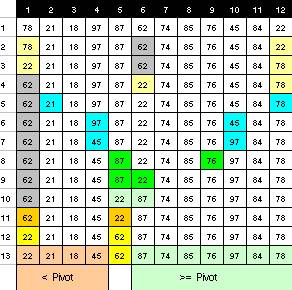
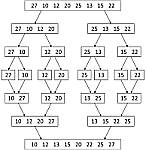
| งานที่มอบหมาย
|
| แหล่งอ้างอิง (Reference) |
| โครงสร้างข้อมูลฉบับภาษาจาวา โดย อ.สมชาย ประสิทธิ์จูตระกูล
| http://www.cp.eng.chula.ac.th/~somchai/ULearn/DataStructures
|
| Source Code by Mark Allen Weiss
| http://users.cs.fiu.edu/~weiss/dsaajava/code/DataStructures/
|
| DS. with JAVA by William H. Ford & William R. Topp
| http://www1.pacific.edu/~wford/fordtopp/javabook/java_index.html
|
| DS & Algo with OOP by Bruno R. Preiss, P.Eng. All
| http://www.brpreiss.com/books/opus5/html/book.html
|
| Dictionary of Data Structure
| http://www.itl.nist.gov/div897/sqg/dads/
|
| โครงสร้างข้อมูลฉบับภาษาจาวา : อ.สมชาย ประสิทธิ์จูตระกูล
| http://www.cp.eng.chula.ac.th/~somchai/ # # # # # # # # # # # # # # |
| Special lecture by Prof. Dr.-Ing. habil. Herwig Unger, Faculty of Mathematics and Informatics, FernUniversitat in Hagen, Germany Topic: Pattern generation in decentralized communities   
|
ไม่มีความคิดเห็น:
แสดงความคิดเห็น